L'obiettivo di Internet Archive, secondo il suo sito web, è ”l'accesso universale a tutte le conoscenze.” Come parte di questa missione, l'impresa no-profit gestisce Wayback Machine, uno strumento online utilizzabile da chiunque per conservare digitalmente la versione temporanea di un sito web. Il sistema fornisce un importante servizio pubblico, in quanto se una società cerca di modificare la sua politica in modo poco chiaro o un governo cerca di nascondere un contenuto dal suo sito web, Wayback Machine ne conserva le prove.
Pubblicità
Ma Internet Archive ha eliminato dalle sue pagine i contenuti relativi a un'azienda che commercializzava potenti malware pensati per partner gelosi che vogliono spiare i loro coniugi.La notizia evidenzia la questione più ampia della fragilità degli archivi on line, compresi quelli che conservano informazioni di pubblico interesse.”I giornalisti e i difensori dei diritti umani spesso si affidano a servizi di archiviazione come Wayback Machine come strumenti per conservare prove che potrebbero essere fondamentali per sottolineare determinate responsabilità,” ha spiegato via chat a Motherboard Claudio Guarnieri, esperto di tecnologia di Amnesty International.
L'azienda in questione è FlexiSpy, dalla sua sede in Tailandia, vende malware per computer desktop e dispositivi mobile. Lo spyware può intercettare telefonate, accendere da remoto il microfono e la videocamera di un dispositivo, rubare e-mail e messaggi dai social, nonché tenere traccia della posizione GPS di un determinato target. In precedenza, le pagine del sito di FlexiSpy salvate su Wayback Machine riportavano un sondaggio tra i clienti in cui oltre il 50% degli intervistati si dichiarava interessato a un prodotto per spiare i telefoni perché credeva che il proprio partner dicesse bugie. Quel sondaggio in particolare è stato citato in un recente articolo del New York Times sul mercato dello spyware rivolti a utenti comuni.
Pubblicità
In un altro esempio, un versione della homepage di FlexiSpy archiviata su Wayback Machine mostrava uno degli slogan dell'azienda: ”Molti coniugi mentono. Tutti usano i telefoni. Il loro telefono cellulare vi dirà quello che non vogliono dirvi.”Ora, quelle pagine non sono più disponibili su Wayback Machine. Quando si prova a visualizzare una pagina qualsiasi dal dominio di FlexiSpy sul servizio di archiviazione, la risposta è ”Questo URL è stato escluso da Wayback Machine.” (Dopo che Motherboard ha pubblicato una serie di articoli sul mercato dello spyware per consumatori comuni, FlexiSpy ha ripulito il proprio sito dai contenuti relativi allo spionaggio illegale dei coniugi).
Uno screenshot di un sondaggio di FlexiSpy precedentemente disponibile su Wayback Machine. Immagine: Screenshot.
”Gli URL sono instabili nel tempo per loro natura. I governi cambiano e cambiano anche i loro contenuti online. Le aziende chiudono, così come i loro siti web. Ma nonostante questo, gli URL di Internet Archive, invece, sono sempre rimasti. Ma non sembra più essere così,“ ha raccontato via chat a Motherboard Thomas Rid, professore di studi strategici presso la Johns Hopkins University.Molti siti utilizzano il cosiddetto protocollo di esclusione robot per impedire ai crawler di archiviare i loro contenuti. Di solito, il proprietario di un sito web carica un semplice file di testo chiamato 'robots.txt', che ordina ai bot di non raccogliere dati dal suo sito.”Nel nostro lavoro di raccolta di documenti pubblicamente disponibili su internet, a volte gli autori e gli editori esprimono il desiderio che i loro documenti non vengano inclusi nelle Collezioni (etichettando un file per la esclusione robot, contattando noi o il gruppo di crawler del caso),” si legge in una sezione delle termini d'uso di Internet Archive. I termini, tuttavia, non specificano che il gruppo esaudisce le richieste di rimozione, ma solo che potrebbe farlo.
”Se l'autore o l'editore di un contenuto memorizzato nell'Archivio non vuole che il suo lavoro sia presente nelle nostre Collection, allora possiamo rimuoverlo senza preavviso,” viene spiegato sempre nei termini d'uso. Internet Archive ha dichiarato in precedenza che non rispetterà i file robots.txt dei domini militari e governativi degli Stati Uniti, anche se potrebbe comunque rispondere alle relative richieste di rimozione.Michael Nelson del Web Science and Digital Libraries Research Groupdella Old Dominion University ha spiegato via mail a Motherboard che ”affinché Internet Archive rimuova qualcosa dal suo archivio, sono necessarie pressioni legali.” Nelson ha anche aggiunto che, di solito, Wayback Machine indica quando le informazioni sono state rimosse a causa di robots.txt e che la sintassi di FlexiSpy nel suo file robots.txt è “non-standard if not wrong.”Diversi membri dell'Internet Archive contattati non hanno risposto alle nostre richieste di commento e chiarimento sul perché il sito abbia eliminato gli archivi di FlexiSpy. Per questo, è difficile capire quale sia il meccanismo — minacce legali o altro — che ha portato l'Archive ad agire in questo modo.FlexiSpy, invece, ha dichiarato in un tweet recente di aver contattato l'Internet Archive, a quanto pare per chiedere di rimuovere i contenuti dell'azienda.
Pubblicità
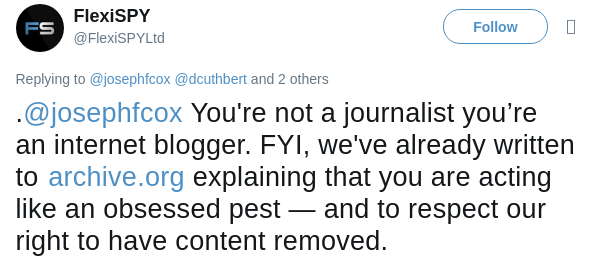
”Abbiamo già scritto ad archive.org spiegando che vi state comportando come parassiti ossessivi — e di rispettare il nostro diritto alla rimozione dei contenuti,” ha twittato FlexiSpy la settimana scorsa, in riferimento alle indagini condotte da Motherboard sull'industria degli spyware consumer. FlexiSpy non ha risposto al messaggio diretto su Twitter che gli abbiamo inviato chiedendo se l'azienda fosse disponibile a condividere una copia della lettera inviata all'Internet Archive.
”Le società di spyware commerciali che cercano di rimuovere i loro documenti sono solo un esempio del motivo per cui abbiamo bisogno di soluzioni di archiviazione resilienti, o per lo meno di chiarezza sulle aspettative di integrità e durata che le persone dovrebbero nutrire nei confronti di questi servizi,” ha spiegato Guarnieri.Non tutti i servizi di archiviazione possono rispettare la esclusione robot o una richiesta di rimozione. Al momento della scrittura, archive.is, ad esempio, non ha problemi a creare uno snapshot del sito di FlexiSpy.”Disporre di un solo archivio web è una debolezza. Abbiamo bisogno di maggiore diversificazione nelle tipo di tecnologia adottata, nelle location geografiche degli archivi (ad esempio, non ospitare l'Internet Archive solo lungo la faglia di San Andreas, nel tipo di organizzazioni e nelle giurisdizioni che li ospitano,” ha spiegato Nelson.“Internet Archive è un'organizzazione e una risorsa straordinaria, ma è costantemente sotto minaccia e queste minacce non faranno che aumentare man mano che il ruolo degli archivi web si espanderà nella nostra sfera pubblica e politica,” ha aggiunto.Il problema di scomparsa o dell'inaffidabilità degli archivi è parte del motivo per cui Motherboard ha creato uno strumento chiamato mass_archive. Questo script in Python di base spedisce una singola pagina web a più servizi di archiviazione in contemporanea, il che significa che se, per esempio, Wayback Machine non ne crea una copia, forse lo farà un'altra libreria digitale.”L'idea che internet non dimentica nulla è una totale assurdità — l'internet pubblico dimentica ogni giorno, come parti conoscenza che preciptano tranquillamente da una scogliera nel mare oscuro del tempo,” ha concluso Rid.Questo articolo è comparso originariamente suMotherboard US.Seguici su Facebook e Twitter.


 ”Le società di spyware commerciali che cercano di rimuovere i loro documenti sono solo un esempio del motivo per cui abbiamo bisogno di soluzioni di archiviazione resilienti, o per lo meno di chiarezza sulle aspettative di integrità e durata che le persone dovrebbero nutrire nei confronti di questi servizi,” ha spiegato Guarnieri.Non tutti i servizi di archiviazione possono rispettare la esclusione robot o una richiesta di rimozione. Al momento della scrittura, archive.is, ad esempio, non ha problemi a creare uno snapshot del sito di FlexiSpy.”Disporre di un solo archivio web è una debolezza. Abbiamo bisogno di maggiore diversificazione nelle tipo di tecnologia adottata, nelle location geografiche degli archivi (ad esempio, non ospitare l'Internet Archive solo lungo la faglia di San Andreas, nel tipo di organizzazioni e nelle giurisdizioni che li ospitano,” ha spiegato Nelson.“Internet Archive è un'organizzazione e una risorsa straordinaria, ma è costantemente sotto minaccia e queste minacce non faranno che aumentare man mano che il ruolo degli archivi web si espanderà nella nostra sfera pubblica e politica,” ha aggiunto.Il problema di scomparsa o dell'inaffidabilità degli archivi è parte del motivo per cui Motherboard ha creato uno strumento chiamato mass_archive. Questo script in Python di base spedisce una singola pagina web a più servizi di archiviazione in contemporanea, il che significa che se, per esempio, Wayback Machine non ne crea una copia, forse lo farà un'altra libreria digitale.”L'idea che internet non dimentica nulla è una totale assurdità — l'internet pubblico dimentica ogni giorno, come parti conoscenza che preciptano tranquillamente da una scogliera nel mare oscuro del tempo,” ha concluso Rid.Questo articolo è comparso originariamente su Motherboard US.Seguici su Facebook e Twitter.
”Le società di spyware commerciali che cercano di rimuovere i loro documenti sono solo un esempio del motivo per cui abbiamo bisogno di soluzioni di archiviazione resilienti, o per lo meno di chiarezza sulle aspettative di integrità e durata che le persone dovrebbero nutrire nei confronti di questi servizi,” ha spiegato Guarnieri.Non tutti i servizi di archiviazione possono rispettare la esclusione robot o una richiesta di rimozione. Al momento della scrittura, archive.is, ad esempio, non ha problemi a creare uno snapshot del sito di FlexiSpy.”Disporre di un solo archivio web è una debolezza. Abbiamo bisogno di maggiore diversificazione nelle tipo di tecnologia adottata, nelle location geografiche degli archivi (ad esempio, non ospitare l'Internet Archive solo lungo la faglia di San Andreas, nel tipo di organizzazioni e nelle giurisdizioni che li ospitano,” ha spiegato Nelson.“Internet Archive è un'organizzazione e una risorsa straordinaria, ma è costantemente sotto minaccia e queste minacce non faranno che aumentare man mano che il ruolo degli archivi web si espanderà nella nostra sfera pubblica e politica,” ha aggiunto.Il problema di scomparsa o dell'inaffidabilità degli archivi è parte del motivo per cui Motherboard ha creato uno strumento chiamato mass_archive. Questo script in Python di base spedisce una singola pagina web a più servizi di archiviazione in contemporanea, il che significa che se, per esempio, Wayback Machine non ne crea una copia, forse lo farà un'altra libreria digitale.”L'idea che internet non dimentica nulla è una totale assurdità — l'internet pubblico dimentica ogni giorno, come parti conoscenza che preciptano tranquillamente da una scogliera nel mare oscuro del tempo,” ha concluso Rid.Questo articolo è comparso originariamente su Motherboard US.Seguici su Facebook e Twitter.