
Imagine being at a bar talking to a group of friends. You’re telling some bar-friendly story that ends with the line, “And that’s the last time I did whippits.” Everyone laughs because it was a funny story—all except for your mate Brian. Brian instead looks horrified, stunned. After some coaxing and reassurance, Brian explains that he didn’t hear the line “And that’s the last time I did whippits” at all. Brian heard you say, “And that was the time I stabbed my brother to death.”
Everyone else agrees that’s not at all what was said, and eventually Brian is convinced as well. But still, he heard what he heard. Something somewhere changed the signal for him only, leading to the aforementioned audio hallucination. Audio hallucinations in human brains are tricky things that happen for a variety of reasons, but it generally reduces to faulty information processing. A misinterpreted signal.
Videos by VICE
It’s hard to imagine how another person might misinterpret a signal that, to us, seems so clear. But we can look to machines—and machine learning—for examples of how speech recognition can go awry, how a simple phrase might be heard as something completely different in the presence of a slight distortion. A pair of computer science researchers at the University of California, Berkeley, Nicholas Carlini and David Wagner, have demonstrated just this, crafting finely-tuned audio hallucinations by tricking the state-of-the-art DeepSpeech speech recognition neural network into transcribing most any audio (speech or even just plain noise) into really whatever they want. Listen to examples here.
“With powerful iterative optimization-based attacks applied completely end-to-end, we are able to turn any audio waveform into any target transcription with 100 percent success by only adding a slight distortion,” Carlini and Wagner report in a paper recently posted to the arXiv preprint server. “We can cause audio to transcribe up to 50 characters per second (the theoretical maximum), cause music to transcribe as arbitrary speech, and hide speech from being transcribed.”
Generally, this sort of attack, where a machine learning algorithm is tricked into reaching the wrong conclusion, is known as adversarial machine learning.
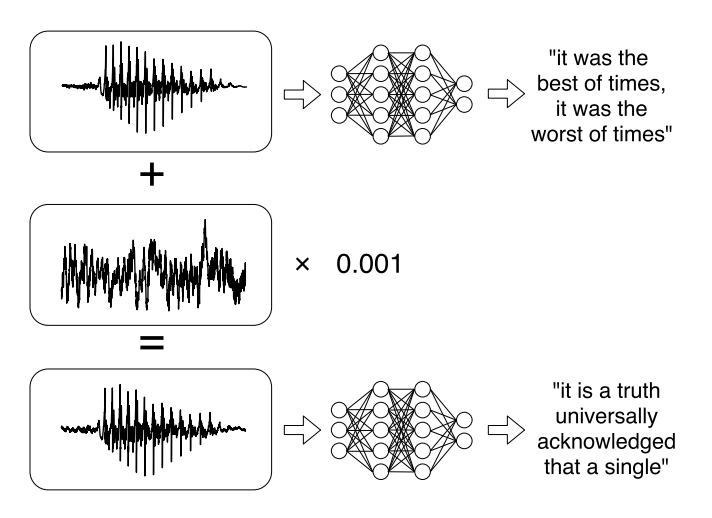
The basic idea is of taking an unaltered audio signal and adding in just the tiniest amount of another, very specifically crafted signal to it. The resulting altered signal is 99.9 percent similar to the original, but the remaining .1 percent is enough to trick the speech recognition neural net. The challenge is then coming up with the perfect .1 percent of new signal.
The process looks like this: The researchers take an input signal (“I heart whippits,” say) and the desired transcription (“I heart fratricide”) and iterate over a whole bunch of possible adversarial signals until they find one that minimizes the error between the actual DeepSpeech transcription and the desired spoof transcription (while still leaving the original signal mostly intact). Basically, the algorithm makes a bunch of educated guesses and then improves on those guesses based on whether or not the error between the target phrase and the actual transcription is increasing or decreasing. This general process is what’s behind a lot of generative/creative machine learning algorithms.
Right now, the adversarial effect of this technique doesn’t work over the air. That is, if the hacked signal is played from a speaker and received by a microphone, the effect is lost.
That said, it’s a safe bet that the technology will improve to the point that open-air audio speech recognition hacking will be possible. A paper released last week by another team of researchers demonstrated a similar technique that hacks music signals instead of speech signals. Crucially, it does work over the air, which means that it’s possible to embed Alexa voice commands within music.
More
From VICE
-

Dave Fleetham/Design Pics Editorial/Universal Images Group via Getty Images -

Photo by Sean Gallup/Getty Images -

Westend61/Getty Images -

Simone Joyner/Getty Images